本报记者 梁傲男
8月11日晚间,北京智谱华章科技股份有限公司(以下简称“智谱”)推出全球100B级效果最佳的开源视觉推理模型GLM-4.5V(总参数106B,激活参数12B),并同步在魔搭社区与HuggingFace开源。
这是智谱在通向通用人工智能(AGI)道路上的又一探索性成果。
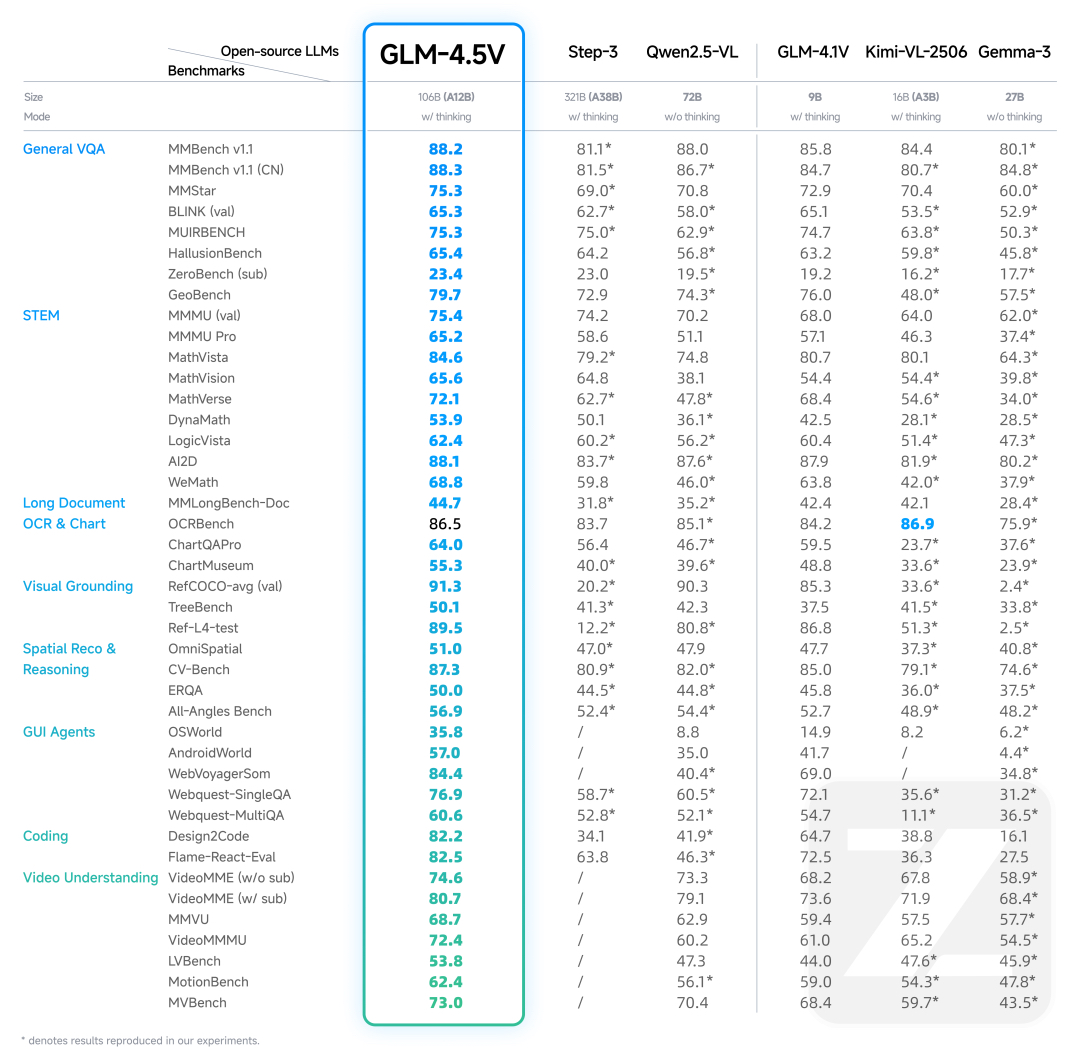
GLM-4.5V基于智谱新一代旗舰文本基座模型GLM-4.5-Air,延续GLM-4.1V-Thinking技术路线,在41个公开视觉多模态榜单中综合效果达到同级别开源模型SOTA性能,涵盖图像、视频、文档理解以及GUIAgent等常见任务。
智谱供图
在多模态榜单之外,智谱更重视模型在真实场景下的表现与可用性。GLM-4.5V通过高效混合训练,具备覆盖不同种视觉内容的处理能力,实现全场景视觉推理,包括:图像推理(场景理解、复杂多图分析、位置识别)、视频理解(长视频分镜分析、事件识别)、GUI任务(屏幕读取、图标识别、桌面操作辅助)、复杂图表与长文档解析(研报分析、信息提取)、Grounding能力(精准定位视觉元素)
同时,模型新增“思考模式”开关,用户可灵活选择快速响应或深度推理,平衡效率与效果。
在保持高精度的同时,GLM-4.5V兼顾推理速度与部署成本,为企业与开发者提供高性价比的多模态AI解决方案。API调用价格低至输入2元/Mtokens,输出6元/Mtokens。
在技术细节方面,GLM-4.5V由视觉编码器、MLP适配器和语言解码器三部分组成,支持64K多模态长上下文,支持图像与视频输入,并通过三维卷积提升视频处理效率。模型采用双三次插值机制,有效增强了模型对高分辨率及极端宽高比图像的处理能力与稳健性;同时,引入三维旋转位置编码(3D-RoPE),显著强化了模型对多模态信息的三维空间关系的感知与推理能力。
此外,GLM-4.5V采用三阶段策略:预训练、监督微调(SFT)和强化学习(RL)。其中,在预训练阶段,智谱结合大规模图文交错多模态语料和长上下文内容,强化了模型对复杂图文及视频的处理能力;在SFT阶段,智谱引入了显式“思维链”格式训练样本,增强了GLM-4.5V的因果推理与多模态理解能力;最后,RL阶段,智谱引入全领域多模态课程强化学习,通过构建多领域奖励系统(RewardSystem),结合可验证奖励强化学习(RLVR)与基于人类反馈的强化学习(RLHF),GLM-4.5V在STEM问题、多模态定位、Agent任务等方面获得全面优化。
多模态推理被视为通向通用人工智能的关键能力之一,让AI能够像人类一样综合感知、理解与决策。其中,视觉-语言模型(Vision-LanguageModel,VLM)是实现多模态推理的核心基础。
今年7月份,智谱发布并开源了全球10B级效果的VLM——GLM-4.1V-9B-Thinking。该模型以小博大,展现了小体积模型的极限性能潜力,上线后迅速登上HuggingFaceTrending榜首,并累计获得超过13万次下载。
(编辑 张明富)
 京公网安备 11010602201377号京ICP备19002521号
京公网安备 11010602201377号京ICP备19002521号















